Hash란?
원소가 저장되는 위치가 원소 값에 의해 결정되는 자료구조
- 평균 상수 시간에 삽입, 검색, 삭제가 가능하다.
- 매우 빠른 응답을 요구하는 상황에 유용
(Hash는 최소(최대) 원소를 찾는 것과 같은 작업은 지원하지 않는다.)
※ Java의 HashMap / C++의 map / Python의 dictionary로 보다 쉽게 이용할 수 있다.
해싱(Hashing) 과정
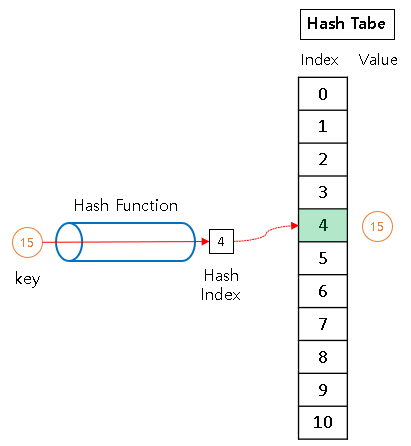
- 해싱(Hashing)
매핑하는 전체 과정
- 키(key)
매핑 전 원래 데이터의 값
- 해시함수(hash function)
데이터의 효율적 관리를 목적으로
임의의 길이의 데이터를 고정된 길이의 데이터로 매핑
- 해시 값(hash value)
매핑 후 데이터의 값 (Hash Code라고도 부름)
Hash 성능과 필요성
- Hash Table → O(1)
- Array를 통한 선형 탐색 → O(N)
- Binary Search Tree → 평균 O(log N) (최악 O(N) )
- Balanced Binary Search Tree → 최악 O(log N)
Hash 예시
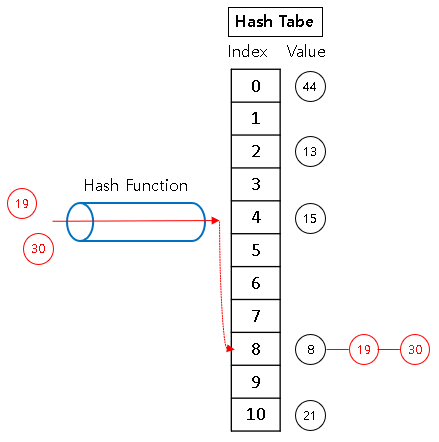
▶ 크기 11인 Hash Table에 5개 원소(44, 13, 15, 8, 21) 저장
▶ Hash Function → hash(key) = key mod 11

hash(44) = 44 mod 11 = 0
hash(13) = 13 mod 11 = 2
hash(15) = 15 mod 11 = 4
hash(8) = 8 mod 11 = 8
hash(21) = 21 mod 11 = 10
Hash 충돌 상황과 해결방법
Q) Hash를 구현할 때, 같은 Hash Index를 가지면 어떻게 해야할까? (Hash 충돌)
아래와 같은 상황에서 원소 {19, 30}을 저장할 때,
Hash Index = 19 mod 11 = 30 mod 11 = 8 로
이미 Hash Index가 존재하는 곳에 Mapping 된다.

▶ Hash Table의 한 주소(index)를 놓고 두 개 이상의 원소가 자리를 다투는 것을 의미합니다.
Hash 충돌은 Chaining (체이닝) 혹은 Open Addressing (개방 주소)
Chaining (체이닝)
같은 주소로 hashing 되는 원소를 Linked list로 관리
원소를 삭제하거나 변경하는 작업이 상대적으로 간단하다.
동일 index에 대해서 데이타를 저장하는 자료 구조는 Linked List가 아니라
Tree를 이용하여 저장하여 탐색(Search)의 성능을 높일 수 있다.
실제로, JDK 1.8의 경우에는 index에 노드가 8개 이하일 경우에는 Linked List를 사용하며,
8개 이상으로 증가할 때는 Tree 구조로 데이타 저장 구조를 바꾸도록 되어 있다.
[해시] Hash Chaining 기법 구현
[해시] Hash란?에 작성한 Hash를 구현하는 방식 중 하나인 체이닝(Chaining) 기법을 구현하였습니다. Hash 개념이 필요하신 분은 먼저 [해시] Hash란?을 참고해주세요 Chaining 기법 Hash Function이나 주어지
zoosso.tistory.com
Open Addressing (개방 주소)
개방 주소 기법에도 여러가지 방식이 존재한다.
- 선형 조사(Linear Probing)
- 이차원 조사(Quadratic Probing),
- 이중 해싱(Double hashing) 등
그 중에서 간단한 선형 조사 방식을 살펴보면, 비어있는 Hash Index를 순차적으로 찾는다.

① "19"를 넣었을 때, Hash Table[8]에 "8" 이 있기 때문에 다음 빈 자리 탐색
→ Hash Table[9]에 "19"가 안착하게 되었다.
② "30"를 넣었을 때, Hash Table[8]에 "8" 이 있기 때문에 다음 빈 자리 탐색
→ Hash Table[9..10..0] 탐색한 후 비어있는 Hash Table[1]에 안착
▶ [해시] Hash Open Address 기법 구현
[해시] Hash Open Address 기법 구현
[해시] Hash란?에 작성한 Hash를 구현하는 방식 중 하나인 체이닝(Chaining) 기법을 구현하였습니다. Hash 개념이 필요하신 분은 먼저 [해시] Hash란?을 참고해주세요 Open Address 기법 Hash Function이나 주어.
zoosso.tistory.com
Q) 이러한 주소개방 기법과 체이닝 기법의 차이는 무엇일까?
- 충돌이 발생했을 경우 연결 리스트(Linked List)같은 추가적인 메모리를 사용하지 않고
해시 테이블(Hash Table)의 빈 버킷(Bucket)을 이용한다.
즉, 외부 공간에 필요한 추가적인 작업이 요구하지 않고, 초기에 Hash Table 공간만 활용
- 메모리 추가할당이 없기에 Data 추가시 메모리 할당 오버헤드가 없으며,
Code 상으로는 메모리 할당자가 없이도 구현이 가능
- 충돌이 발생하면 다른 버킷(Bucket)에 저장하기 때문에 데이터의 주소 값(인덱스)이 바뀝니다.
이는 임의의 Data에 대한 명확한 Hash Index를 예측할 수 없게 되는 것을 의미한다.
- 선형 검색법(Linear Probing)에서 Chaining보다 뛰어난 참조 지역성을 가진다.
→ 적은 데이터의 Lookup 연산에서 보다 좋은 성능을 보인다.
※ 참조 지역성이란? Locality of reference, 하나의 자원에 여러번 접근하는 프로세스
결론
두 가지 Hash 충돌 해결방법을 보았는데,
사실 충돌이 잦으면 해시 최대 장점인 key를 통해 O(1)만에 value를 가져온다고 볼 수 없다.
따라서 충돌을 최소화하기 위해서는 Index Mapping 자체를 효율적으로 구현해야 한다.
※ 해시함수의 종류 : MD1, MD4, MD5, SHS, SHA-1, HAS-160 등
좋은 Hash 함수의 조건
- 입력 원소가 Hash table에 골고루 저장되어야 합니다.
- Hash Function 자체가 복잡하다고 무조건 좋은 것이 아니다.
PS에 있어서는 어느정도 간단한 계산이 적합하며,
암호학의 경우 보안을 위해 복잡해야 한다.
해시 테이블이 적합하지 않은 경우들
- 정렬된 데이터가 필요할 때
- 멀티미디어 데이터를 저장할 때
- 키의 길이가 길고 가변적이어서 키에 대한 사전 검색이 필요할 때
- 조건에 따라 데이터가 동적으로 변해야 할 때
- 데이터의 키가 유일하지 않을 때
즉, 연속적인 데이터 검색에는 비효율적이며
만약 해시 테이블을 재구성해야한다면 새로 모든것을 만들어야하기에 비효율적일 수 있다.
Reference
- [해시] Hash Open Address 기법 구현
관련 문제
- [BOJ] 7453 합이 0인 네 정수 (Chaining + Open Addressing)
- [BOJ] 7785 회사에 있는 사람 (문자열 Hash)
- [Jungol] 3142 ID 검사 (원소값 삭제하는 경우)
- [BOJ] 3033 가장 긴 문자열 (문자열 Hash, Rabin-Karp, Rolling Hash)
- [BOJ] 1764 듣보잡 (Java, HashMap Collection 이용)
- [Jungol] 3706 합이 0이 되는 연속구간 세기

'자료구조' 카테고리의 다른 글
| [해시] Hash Open Address 기법 구현 (0) | 2021.05.01 |
|---|---|
| [해시] Hash Chaining 기법 구현 (0) | 2021.05.01 |
| [큐] 원형 큐 (Circular Queue) (0) | 2021.04.24 |
| [큐] Queue란? (2) | 2021.04.23 |
| [스택] Stack 이란? (0) | 2021.04.22 |





댓글