LCP (Longest Common Prefix)
LCP는 두 접미사의 최대 공통 접두사의 길이를 의미
※ 앞서 접미사 배열(Suffix Array)에 대해서 알고 있어야 합니다.
접미사 배열(Suffix Array)
접미사 배열(Suffix Array) 접미사 배열은 문자열 S의 모든 접미사를 사전순으로 정렬해 놓은 배열. ex) S = "banana"에는 접미사가 총 6 개 있습니다. "banana", "anana", "nana", "ana", "na", "a" ▶Suffix..
zoosso.tistory.com
ex) 문자열 S = "banana"
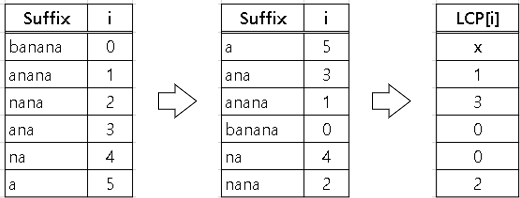
Suffix Array에서 LCP(최대 공통 접두사)를 구하는 방법은 아래와 같습니다.
① 『a』 이전 값 존재 x → LCP[1] = x
② 『a』 와 『ana』의 LCP[2] = 1
③ 『ana』 와 『anana』 의 LCP[3] = 3
④ 『anana』 와 『banana』 의 LCP[4] = 0
⑤ 『banana』 와 『na』 의 LCP[5] = 0
⑥ 『na』 와 『nana』 의 LCP[6] = 2

- 두 단어를 가지고 비교하는 경우에는 O(N2) 소요
- Kasai’s Algorithm으로 구현 가능 O(N × logN)
LCP 구현
LCP[]는 Kasai’s Algorithm을 이용하며 다음의 순서로 구해집니다.
▶ 『banana』 → 『anana』 → 『nana』 → 『ana』 → 『na』 → 『a』
LCP[i]를 구하기 위해서는 Suffix[i]와 Suffix[i+1]이 필요합니다.
※ LCP[i] = (Suffix[i]와 Suffix[i+1] 가장 긴 공통 접두사)
suffix[]에서 다음 접미사를 찾으려면 invSuff[] 배열 이용.

① 『banana』에서 다음 접미사는 『na』 입니다.
『banana』와 『na』 사이에는 공통 접두사가 없으므로 LCP[3] = 0

② 『anana』에서 다음 접미사 『banana』 입니다.
공통 접두사가 없기 때문에 LCP[2] = 0

③ 『nana』 다음 접미사가 없으므로 LCP 값은 정의되지 않습니다.
(임의로 LCP[5] = 0으로 할당)

④ 『ana』의 다음 접미사는 『anana』 입니다.
공통 접두사 길이 = 3이므로 LCP[1] = 3

⑤ 『na』는 이전 LCP 값이 3이기 때문에 이번에는 2 이상이어야 합니다.
『na』는 두글자로 뒤에 문자가 없으므로 LCP[4] = 2

⑥ 『a』는 이전 LCP 값이 2이므로 이번에는 1 이상이어야 합니다.
『a』는 한글자로 뒤에 문자가 없으므로 LCP[0] = 1 입니다.

★ 위의 계산은 Suffix Array와 LCP 특성에 근거해서 구현됨.
Reference

'알고리즘' 카테고리의 다른 글
| Binary Search (이분 탐색) (0) | 2021.03.06 |
|---|---|
| 계수 정렬(Counting Sort) (0) | 2021.03.06 |
| [탐색] Parametric Search (0) | 2021.03.04 |
| PS시 어떤 정렬을 선택하는 것이 좋을까? (0) | 2021.03.02 |
| 합병 정렬(Merge Sort) (0) | 2021.03.02 |





댓글