Hash 구현 (양방향, 더미노드 0개, *head)
Hash 구현에 있어서 중요한 것은 Hash Function을 통해서
key → Hash Index로 변환되는 결과에서 중복 Hash Index가 적게 발생하는 것이다.
즉, 충돌을 적게 발생시키는 것이 효율적인 Hash Function 이다.
Hash Function을 잘 만든다면 충돌 처리를 할 필요는 없지만,
보장할 수 없는 경우라면 크게 Chaining 기법과 Open Address 기법으로 해결할 수 있다.
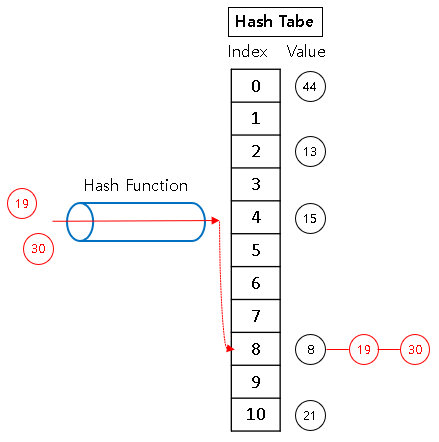
[해시] Hash란?
Hash란? 원소가 저장되는 위치가 원소 값에 의해 결정되는 자료구조 - 평균 상수 시간에 삽입, 검색, 삭제가 가능하다. - 매우 빠른 응답을 요구하는 상황에 유용 (Hash는 최소(최대) 원소를 찾는 것
zoosso.tistory.com
[해시] Hash Chaining 기법 구현
[해시] Hash란?에 작성한 Hash를 구현하는 방식 중 하나인 체이닝(Chaining) 기법을 구현하였습니다. Hash 개념이 필요하신 분은 먼저 [해시] Hash란?을 참고해주세요 Chaining 기법 Hash Function이나 주어지
zoosso.tistory.com
구조체 정보
- 각 Hash Index에 해당하는 연결리스트 구현
- new / delete 보다는 Memory Pool 방식으로 정적할당 받은 공간에 할당
struct Node {
int id;
Node* prev, * next;
Node* alloc(int _id, Node* _prev, Node* _next) {
id = _id, prev = _prev, next = _next;
if (prev) prev->next = this;
if (next) next->prev = this;
return this;
}
void pop() {
if (prev) prev->next = next;
if (next) next->prev = prev;
}
}buf[MAX_N], * head[SIZE];
int bcnt;bcnt : 현재 사용된 buffer 개수
처음 정적 할당받은 buf[MAX_N]에서 가져다 사용한다.
*head[size] : 각 Hash Index 연결리스트의 첫번째 위치
key값이 존재하는지 확인할 때는 해당 연결리스트를 탐색한다.
초기화
void init() {
bcnt = 0;
for (int i = 0; i < SIZE; ++i) {
head[i] = 0;
}
}- Test Case가 1개라면 필요없지만, 여러 Test Case가 존재하는 경우에는
Hash Table을 Clear 해주어야 한다.
- 지금까지 할당해준 buf[]의 개수를 「0」 으로 해준다.
- 각 연결리스트 첫번째를 가리키는 head[]를 NULL(0) 처리
추가 (삽입)
for (int i = 0; i < N; ++i) {
int key = hash(id[i]);
head[key] = buf[bcnt++].alloc(id[i], 0, head[key]);
}- buf[]에서 bcnt 번째를 할당해준다.
→ new를 통해서 노드를 생성해준다고 볼 수 있다.
- 해당 노드에 필요한 정보들을 함께 할당 해주는데,
연결리스트의 첫번째 위치에 추가되므로 이전 노드를 가리키는 *prev = 0
다음 노드를 가리키는 *next는 현재 head[]가 된다.

- 추가 함수를 구현할 때는 아래 두 가지 사항에 유의해야 한다.
- 비어있는 연결리스트에 추가하는 경우
- 원소가 이미 존재하는 연결리스트에 새로운 원소 추가하는 경우
삭제
void remove(int id) {
Node* tg = probing(id);
if (tg) {
tg->pop();
// Header에 위치한 경우에 따른 처리
int key = hash(id);
if (tg == head[key])
head[key] = tg->next;
}
}- 삭제할 때는 아래 Case를 고려한다.
- 중간에 위치한 원소를 삭제하는 경우
- 첫번째 원소를 삭제하는 경우 (삭제 후 다른 원소가 존재)
- 마지막 위치한 원소를 삭제하는 경우
- 삭제 후 연결리스트가 비워지는 경우

pop 함수를 보면, 이전/다음 Node가 존재하는 경우에 포인터 연결 처리해준다.
앞/뒤로 비어있는 더미노드를 구현한다면 if 문이 필요없긴하지만
런타임 오류 방지를 위해 습관적으로 연습해두면 유용하다.
전체 Code
- key 충돌을 Open Addressing이 아닌 Chaining 기법으로 처리
- id 값을 가지는 Node 객체는 20개로 제한 (여유로운 크기를 위해 + 5)
- Stack처럼 새로운 Node가 앞쪽에 push (head 위치)
- key 값은 return id % 10;으로 간단하게 처리
#include <stdio.h>
const int MAX_N = 20 + 5;
const int SIZE = 10;
struct Node {
int id;
Node* prev, * next;
Node* alloc(int _id, Node* _prev, Node* _next) {
id = _id, prev = _prev, next = _next;
if (prev) prev->next = this;
if (next) next->prev = this;
return this;
}
void pop() {
if (prev) prev->next = next;
if (next) next->prev = prev;
}
}buf[MAX_N], *head[SIZE];
int bcnt;
int hash(int id) {
return id % 10;
}
void init() {
bcnt = 0;
for (int i = 0; i < SIZE; ++i) {
head[i] = 0;
}
}
void print() {
for (int i = 0; i < SIZE; ++i) {
Node* p = head[i];
// 연결리스트에 원소가 존재하는 경우
if (p) {
printf("[%2d]: ", i);
for (; p; p = p->next) {
printf("%d - ", p->id);
}
printf("\n");
}
}
printf("\n\n");
}
Node* probing(int id) {
int key = hash(id);
Node* p = head[key];
for (; p; p = p->next) {
if (p->id == id)
return p;
}
return 0;
}
void remove(int id) {
Node* tg = probing(id);
if (tg) {
tg->pop();
// Header에 위치한 경우에 따른 처리
int key = hash(id);
if (tg == head[key])
head[key] = tg->next;
}
}
int main() {
int N = 20;
int id[] = {
10, 110, 1010, 22, 12,
52, 777, 93, 19, 90,
63, 5, 4242, 42, 555,
333, 88, 878, 123, 789,
};
init();
for (int i = 0; i < N; ++i) {
int key = hash(id[i]);
head[key] = buf[bcnt++].alloc(id[i], 0, head[key]);
}
print();
remove(1010); print(); // 중간 원소
remove(90); print(); // 첫번째 원소
remove(10); print(); // 마지막 원소
remove(110); print(); // head[0] 연결리스트가 비워지는 경우
}
- 추가될 때, *head[]에 Data가 추가된다. (as Stack)
그렇기에 첫번째 원소를 삭제하는 경우에는 head[]에 가르키고 있는 Node 처리 필요
해당 head[key] 연결리스트 다른 원소가 존재하거나 존재하지 않는 경우이다.
- 더미노드를 만들지 않기 때문에 buf[] 초기화할 때, 추가 개수 고려하지 않는다.
Reference
- Hash (양방향, 더미노드 2개, *head, *tail)
- Hash (양방향, 더미노드 2개, head, tail)

'자료구조' 카테고리의 다른 글
| Hash (단방향, 더미노드 0개, *head) (0) | 2021.06.08 |
|---|---|
| Hash (양방향, 더미노드 1개, *head) (0) | 2021.05.28 |
| 원형 큐 (Circular Queue) 동적할당 + Memory Pool 방식 (0) | 2021.05.07 |
| [큐] Queue (Memory Pool 방식 구현) (0) | 2021.05.02 |
| [큐] Queue (동적할당, 연결리스트 구현) (0) | 2021.05.02 |





댓글